Zunächst mal, danke an Chessguru für die Wiedereröffnung! Und in der Hoffnung, daß die Wiederschließung sich nicht als notwendig erweist.

Zitat von
Egbert
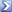
a) mögliche Hashtables-Kollisionen bzw.
Das wird zwar gerne als Ausrede benutzt, wenn ein Programm patzt, ist aber praktisch bedeutungslos. Zwar sind Indexkollisionen häufig, aber es wird an der Position ja auch noch der eigentliche Hashkey gespeichert. Das Paper ist leider nicht mehr online verfügbar, aber Robert Hyatt (Crafty) hat das untersucht. Ergebnis: Ab 48bit Schlüssellänge spielen Hashkollisionen keine Rolle mehr.
Wenn man einen besten Zug in der Tabelle mit gespeichert hat, kann man auch untersuchen, ob der denn pseudolegal ist. Hyatt hatte lange Jahre in Crafty dieses Überprüfungs-Feature, welches ihm zufolge auch nie angeschlagen hat.
Zitat von
Wolfgang2
Ich vermute: Die Portierung des Lang-Programms auf ARM-Coretex ist mit einer so hohen "Verlustleistung" was die Geschwindigkeit angeht, verbunden, dass die - ich sage mal effektive Leistung - etwa dem eines 68030-Prozessors, vielleicht auch etwas mehr, entsprechen könnte (!).
Man muß hierbei erstens sehen, daß die 68k-Versionen direkt in Assembler waren, die ARM-Versionen nicht. Zweitens ist 68k eine CISC-Architektur, während ARM RISC ist. Das bedeutet u.a., daß man bei ARM eine load/store-Architektur hat, anders als bei 68k. Speziell der 030 hatte einen anständigen Cache, durch den das ansonsten damals langsame Speicher-Interface drastisch beschleunigt wurde, was bei den Befehlen zur direkten Speichermanipulation (erhöhe den Inhalt von Adresse sowieso um eins) wichtig war - und solche Befehle gibt es auf ARM gar nicht erst.
Ich entsinne das nicht mehr auf 68k, wohl aber auf Motorola 56k-DSPs, die ich noch in Assembler bearbeitet habe. Da gab's schon eine Pipeline, daß also Befehl Sowieso auf Register Bla erst im Takt DANACH Auswirkungen hatte. Wenn man das geschickt gemacht hat, mit Interleaving der Befehle, dann konnte man die Befehlszahl pro Takt drastisch erhöhen. Richard Lang ist definitiv einer von der Klasse, die sowas draufhatten. Und dann relativierte es sich auch, daß die CISC-Befehle mehr Takte brauchten.
Quintessenz: Man kann die Taktfrequenzen nicht so direkt vergleichen.
Nicht zu vergessen ist auch, daß man in C deutlich anders als in Assembler programmiert und dabei auch in etwa seinen Compiler kennen muß. Ich weiß nicht, wie es bei Lang ist, aber ich halte es auch für denkbar, daß er mit C nicht so richtig warmgeworden sein könnte. Ich habe bei Talkchess C-Code von Ed Schroeder gesehen, und dem merkt man an, daß er in Assembler denkt. Wenn man das mit C macht, geht das zwar, nur ergibt das C-Idiome, für deren Optimierung der Compiler nicht ausgelegt ist.
Übrigens, zu der Anregung, man könnte ja auch mal mehr Speicher für die Hashtables verbauen: Ja, das geht. Ich weiß das im Details nur von STM32, der hat einen "flexible memory controller", mit dem er auch externen Speicher ansprechen kann (auf Kosten von IO-Pins).
ABER: Erstens läuft der dann ohnehin nur mit der halben Geschwindigkeit wie das interne RAM, und zweitens muß man auf dem Bus Daten und Adressen kommunizieren, während das interne RAM sowas wie einen eigenen Datenbus kennt. Drittens wird externes RAM oft genug nur mit 16bit angebunden, besonders, wenn das Marketing dieses Detail verschweigen kann. Dadurch wird es dann noch langsamer.
Daß das externe RAM um (mindestens) einen Faktor 6-9 langsamer als das interne ist, das ist absolut realistisch. Dadurch würde die Spielstärke nicht so stark steigen, wie man es rein der Tabellengröße nach erwarten könnte.
viele Grüße, Rasmus